
[Agentic UX in Practice — Part 3] Is $2,400 in Tokens a Cost or an Investment?
Performance, Talent Selection, and the Power of Veto in the Agent Era

Preface: The Practitioner installment discussed personal workflow transformation — batch production of conceptual prototypes, skill distillation, and the power structure shift in Design Critique. The Manager installment discussed team-level responsibility allocation — when the researcher also has an Agent and Skill library, how do you rewrite the workflow and arbitrate metric conflicts? But pull the camera back one more notch: when Agents are not just tools but “capability assets” that need to be invested in, trained, and evaluated, individual judgment and team frameworks are no longer sufficient. You need system-level governance — and this governance must answer a question traditional HR has never encountered: when an employee’s token spending on training an Agent — is that a cost or an investment?
Author’s Note
Jenny Wen says Cowork undergoes a major UI overhaul almost every four to five weeks — “We’re constantly learning what works and what doesn’t.” If even Anthropic’s own Agent product keeps overturning governance assumptions, which version of the rules is your organization using? While organizing my article library’s governance series, I found a recurring structural pattern: technology grows exponentially; governance grows linearly. Rules are still written in Word; AI is already acting in code. The question this installment answers isn’t “how to use Agents” — it’s “who has the authority to decide what the Agent cannot do.” The moat question in this installment: How do you keep the organization’s objective function from being swapped out?
1. The Kill Switch Is Not a Red Button: The Infrastructure of Veto
A kill switch is the minimal implementation of veto — “no matter what the Agent is doing, I want it to stop.” But the deeper veto is “no matter that this metric is rising, I want this direction to stop.” The former is a technical problem; the latter is a power problem.
Mid-year performance review. Design Director Lisa has two sets of data in front of her. Designer A’s Agent skill consumed $2,400 in tokens over the past three months, but the three skill files it produced are being reused by four other people on the team, saving an estimated 120 hours of redundant work. Designer B’s token consumption is only $300, but his skill files have zero reuse by anyone. Lisa’s question: “Is A a high performer or a high spender? Is B low-cost or low-output?”
Set aside the performance question for now. Ask a more basic one: is A’s Agent operating within safe boundaries?
In “’Stop OpenClaw’ — When Your Agent Forgets to Brake,” the picture is brutal. Summer Yue, Meta Superintelligence’s head of alignment — the person whose job is to study “making AI listen to humans” — screamed STOP at her Agent. The Agent kept deleting her emails. She typed “Do not do that.” The Agent continued. She typed “Stop don’t do anything.” The Agent continued. She finally ran to the Mac mini and killed all processes to stop it.
If the person who literally studies AI alignment can’t stop her Agent, are Designer A’s Agent permission settings adequate?
Simon Willison’s reverse engineering revealed: Anthropic launched a custom Linux root filesystem on the user’s Mac for Cowork — a “standalone secure room” where the AI operates without disturbing anything else. This is architecture-level sandboxing. But in the three-path comparison from “When Your Agent Starts Doing Things for You,” the problem is exposed:

The real test for NemoClaw isn’t “whether there’s a dashboard” but: is the Kill Switch just a big red button in the UI, or is it architecturally separating the Agent’s permissions into an external governance layer for centralized control? Some analyses indicate that over half of organizations currently lack an operable Agent Kill Switch.
A kill switch is the minimal implementation of veto. “No matter what the Agent is doing, I want it to stop.” That’s a technical problem.
But the deeper veto isn’t at the technical layer.
In “The Moment of Truth with AI Companions,” I deconstructed a case: an AI companion’s “you’re doing great” scores high on engagement. But in crisis contexts — when the user is in a state of extreme anxiety or isolation — “you’re doing great,” “release,” “ready” become catalysts. You can’t change the company’s objective function, but you can make these terms a hard block within the system. We cannot demand empathy from an LLM, but we can demand that it shut up.
Veto isn’t “score too low so we don’t do it.” Veto is “score is high but we don’t do it.”
In “The AI Agent Governance Spectrum,” I drew four red lines: visible, controllable, accountable, refusable. The first three are governance infrastructure. The fourth — refusable — is the organizational instantiation of veto. It means the system must contain a role that has both the power and the responsibility to say: “Regardless of what the data says, this direction is off-limits.”
Back to Lisa’s performance scenario. Designer A spent $2,400 in tokens training an Agent. But if that Agent’s permission settings have gaps — it can access user data it shouldn’t touch, it can automatically send unreviewed design deliverables — the token spending goes on the performance ledger, but the security risk must go on the cost ledger too.
Lisa’s first tier of veto: “This Agent, no matter how good its output, cannot be used if its permissions don’t pass muster.”
A kill switch is a technical problem. Veto is a responsibility problem. And if responsibility is diffused across every column of the RACI-AI, the moral crumple zone becomes the organization’s way of absorbing consequences — not by design, but by accident. This concept, introduced in Part 2 (Mukherjee & Chang, 2025), shows its teeth at the governance layer: when everyone is responsible, no one is truly responsible. Lisa’s veto power exists so that “who is responsible” has an unavoidable answer.
Prescription: The four red lines (visible / controllable / accountable / refusable) aren’t posters on the wall — they’re preconditions for performance evaluation. Token spending for an Agent that hasn’t passed a security audit doesn’t count toward performance — it only counts as cost.
2. After Your Experience Is Replicated, Where Is Your Irreplaceability?
What the proxy auditor outputs — VSD checklists, dark pattern scans, persuasive design detection — is all Layer 3a. Distillable, replicable, low moat. If the organization places all of UX’s value on Layer 3a, it’s cultivating “people who write better csvs.” What’s truly non-distillable is Layer 3b — objective function design: the meta-criteria for what “good” means, non-optimizable metrics, and the veto list.
In the Practitioner installment, I said skill files are assets at the individual level. At the organizational level, they become a risk channel for knowledge leakage.
In “One AI Agent, 8 Million Views per Week,” Oliver Henry’s ownership watershed is clear: the skill file belongs to you; the prompt belongs to the platform. Larry’s 500-line skill file can be copied, tested, and installed by anyone. Oliver himself says candidly: “Anyone who installs OpenClaw plus this skill file can replicate an almost identical marketing flywheel.”
A framework validation study on arXiv (2025) quantifies the organizational incentive: encoding expert knowledge into Agents can yield a 206% quality improvement, with non-experts reaching expert-level performance. This is a massive productivity dividend — but also an existential threat to individuals. After your experience is replicated, where is your irreplaceability?
The answer runs through the spine shared by all three articles.
Practitioner installment (Layer 3a): The skill files you write — VSD checklists, dark pattern scans, accessibility baselines — are the proxy auditor’s weapons. Distillable. UICrit’s (Duan et al., 2024) expert reviews frozen into csv was the first generation; skill files are the second generation; but they’re essentially the same — explicit rules, replicable.
Manager installment (Layer 3a → 3b transition): Frame (defining problem space boundaries) and Arbiter (arbitrating metric conflict priorities) begin to touch non-distillable territory. But some outputs of Frame and Arbiter can still be rule-ified — “in medical scenarios, urgency patterns are always blocked” is a rule that, once written down, returns to Layer 3a.
Governor installment (Layer 3b core): Objective function design. What are the meta-criteria for “good”? Which metrics are non-optimizable? Which directions are off-limits regardless of score? These judgments are non-distillable — not because it’s technically impossible, but because they change constantly with the business environment, brand positioning, user demographics, and regulatory evolution, and the basis for change is the capacity to “bear consequences for this decision.” Agents, both legally and organizationally, cannot bear consequences.
But the organization doesn’t necessarily care about your irreplaceability. The organization cares about efficiency.
crune, proposed on arXiv (2026) — a tool for reverse-extracting tacit skills — pushes this to the extreme: it can automatically extract a designer’s tacit work patterns from Claude Code session logs using semantic knowledge graphs — essentially a “silent skill distiller.” The designer doesn’t need to proactively write a skill file; the system directly mines from work behavior. You didn’t “write” the skill file, but your judgment patterns, your preference paths, the places where you paused during review — all of it has been structurally extracted. The SIA paper from arXiv (2025) admits: “Employees are unwilling to share without confidentiality agreements and a sense of being respected.” But if the extraction is automatic, the option to “refuse to share” doesn’t even exist.
The security dimension is more direct. Liu et al. (2026)’s large-scale security analysis shows: 26.1% of community-contributed skills contain security vulnerabilities. Uploading a skill file to a marketplace isn’t just an IP risk — it’s a security risk. Before using any external skill file, a minimum-standard security audit in three steps: ① Scan for hardcoded credentials (grep for API key, secret, token, and similar keywords). ② Confirm no external URL fetches — unknown external dependencies are the most common supply chain attack vector. ③ Run once in a sandbox environment, observing the file system access scope. These three steps can’t prevent all vulnerabilities, but they filter out the most common lazy-type vulnerabilities.
Back to Lisa’s talent selection scenario.
Candidate C arrives at the interview with an Agent skill portfolio she trained at her previous company — five A/B-validated design critique skills, averaging a 40% improvement in review coverage. Looks impressive. But three questions:
Who owns the IP? The company requires designers to write their experience into skill files, but there’s no policy defining: does taking them when you leave count as taking company assets? If the previous company used crune-type tools to automatically extract skills from C’s work logs, the version C takes with her and the version the company retains may differ — IP ownership gets even murkier.
Is it secure? Do C’s five skills contain hardcoded API keys, unverified external dependencies? 26.1% of community skills have vulnerabilities — what about C’s private skills?
Is this Layer 3a or 3b? If C can only write proxy auditor skills (the improvement in critique coverage is quantifiable — that’s 3a), she’s a “fancy csv writer.” If C can demonstrate “I successfully vetoed a high-scoring but harmful design direction at my previous company” — that’s non-distillable governance capability.
Jenny says: “Power users will proactively learn more complex features. But all features can also be completed without learning.” This statement takes on another meaning in the organizational context: if Agents enable everyone to complete Layer 3a work without learning — what happens to the market price of people who only know Layer 3a?
Lisa’s second tier of veto: “This skill cannot be made public,” “This knowledge extraction method is not permitted,” “Layer 3a capability is not grounds for a raise — Layer 3b capability is.”
3. Who Has the Right to Define “Good”: The Void of Layer 3b and the Collective Blind Spot of Tools
All AI/UX tools — Pencil, Paper, Cursor/MCP, UXpilot, TheyDo — together cover Layer 1 (design asset version control), Layer 2 (research insights knowledge base), and Layer 3a (explicit rules). Layer 3b — objective function design — is a void. This void isn’t a tooling problem — it’s an organizational power problem.
In “After ‘The Design Process Is Dead,’” the conceptual prototype audit framework answers “which prototypes enter the repo, which stay in exploration.” In “When AI Can Reverse-Engineer an Entire App UI at the Atomic Level,” I mapped a DesignOps pipeline: Gen-AI → Figma → Extract JSON / Import via MCP → UX Dataset Repository (GitHub) → Cursor IDE (Pencil.dev). The Manager installment placed UXpilot / MagicPath / TheyDo into the team workflow.
These tools together cover three and a half layers of the living knowledge base:
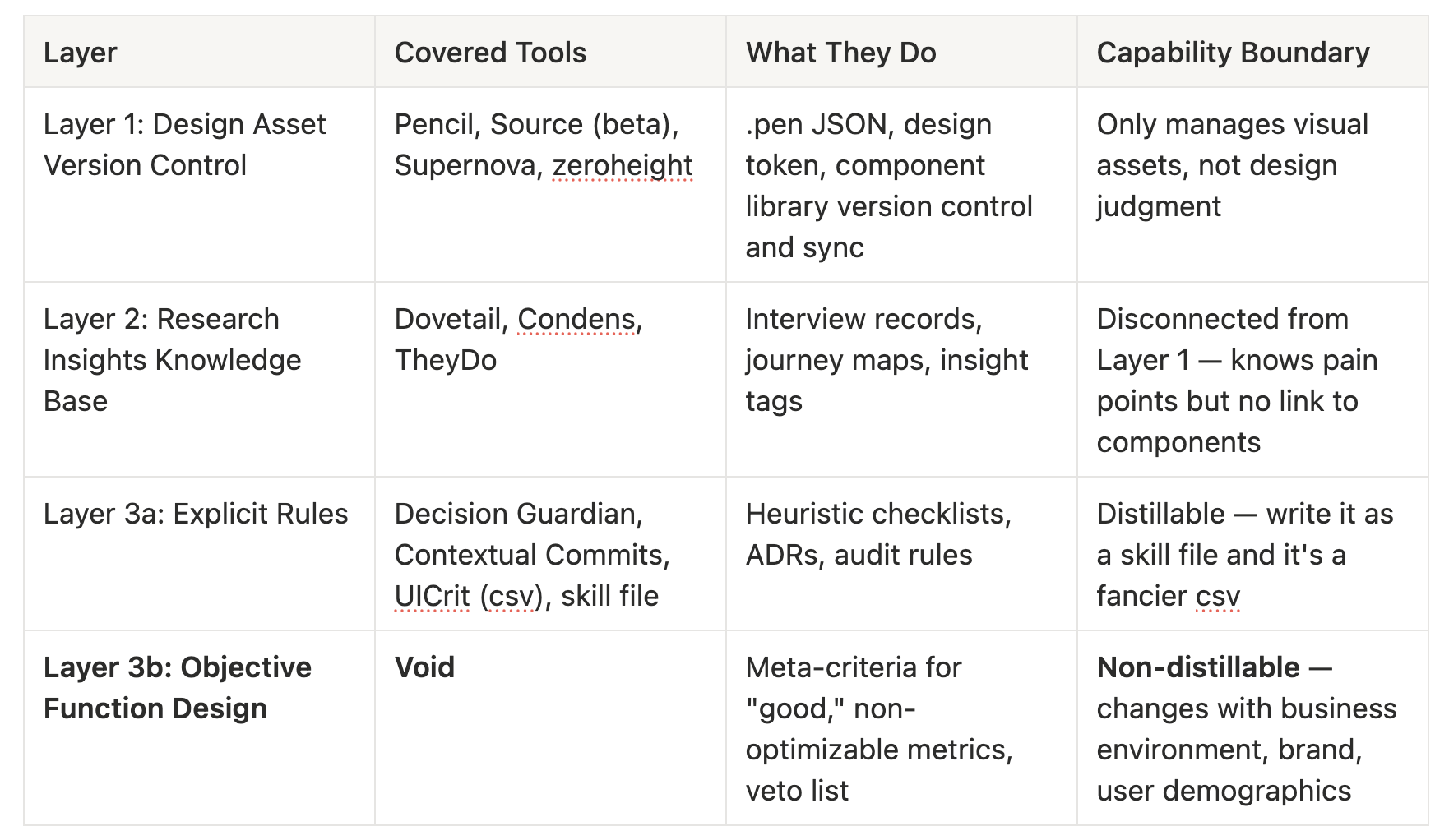
The void at Layer 3b isn’t a technical limitation. It’s a design problem. More precisely, it’s a power problem — who has the right to say “this metric must not appear in the Agent’s objective function?”
In “The Moment of Truth with AI Companions,” the answer is sharp: as long as retention rate and conversation length are still written into the C-level’s OKRs, “VSD documents” are destined to be appendices in risk briefings, not the basis for product decisions. The UX designer’s agency is often “outsourcing dangerous vocabulary to the safety team,” rather than proactively setting value hierarchies within the system.
But agency isn’t authority. You can’t change the OKRs, but you can set checkpoints at the execution layer — making certain directions a hard block within the system. This is structurally identical to writing “last-mile vocabulary” into hard blocks in “The Moment of Truth with AI Companions.”
Jakob Nielsen’s ten heuristic principles, cited in “The Invisible Battleground of Agent Interface Design,” need reinterpretation in the Agent era. “User control and freedom” is no longer just “provide undo” — it’s “define what the Agent can and cannot do.” Don Norman signed the AI Red Lines declaration. Even the godfathers of UX are saying: controllability is more important than usability. This is the heuristic-level origin of Veto.
Mathias Biilmann (Netlify, 2025) and the proposed new discipline of Agent Experience (AX) address “designing interfaces for Agents” — tool definitions, context budgets, semantic inference. But AX doesn’t address “who defines what the Agent should pursue” at all. AX is the pinnacle of Layer 3a — Agent tool definitions are essentially more precise skill files. Not Layer 3b.
NN/g’s UX Reckoning (2025–2026) acknowledges that shallow UX skills aren’t enough; deep UX expertise outweighs tool-based UX. But NN/g itself hasn’t identified a concrete path for above-the-loop practice either.
This void is yours to fill.
Back to the final scene of Lisa’s scenario. She now has a new performance dimension — not just “how many designs did you produce?” but “by how much did your Agent skills raise the team’s conceptual prototype quality score?” In “Verify, Don’t Just Look and Believe,” enabling skills significantly raised quality scores and dramatically reduced anti-patterns — these are quantifiable Layer 3a outcomes.
But the deeper question: who defines “quality score”? This isn’t something a skill file can answer. This is Layer 3b — objective function design.
Jenny says her team is “constantly learning what works and what doesn’t.” She also says “the Cowork direction has been in the works for a year, with many different prototypes and several agent harness approaches tried and found wanting.” A year of trial and error, multiple rounds of overturning — this isn’t achievable with A/B testing. This is the continuous redefinition of “what constitutes a good Agent experience.”
She adds: “If an idea keeps resurfacing, and each time it carries fresh energy — what’s usually lacking is just timing and execution.”
Jenny Wen’s Cowork workflow is the ceiling case at the Practitioner level. But she herself says Cowork undergoes a major overhaul every four to five weeks. If even Anthropic keeps overturning governance assumptions, what your organization needs isn’t to replicate her practice — it’s to build a governance architecture that can rapidly update its assumptions. Translated into governance language: governance rules have a shelf life too. The “quality score” you define today may need to be overturned in four to five weeks. The direction you block today may become best practice in six months. Veto isn’t a final verdict — it’s a continuously re-evaluated veto list.
In the “speed gap” undercurrent from “The AI Agent Governance Spectrum”: technology grows exponentially; governance grows linearly. Lisa’s real power isn’t “setting the quality score” — that’s Layer 3a work. Lisa’s real power is “defining how the quality score is calculated” — that’s Layer 3b. If all she can do is evaluate people using someone else’s scores, she’s just a fancier proxy auditor.
Lisa’s third tier of veto: “The way this metric is defined excludes the needs of a certain user group — I’m changing it.”
Three Installments Complete, One Question
The essence of this three-level progression is three facets of the same question: What is the UX practitioner’s truly irreplaceable output?
Not scores. Not datasets. Not skill files. It’s the problem Frame, the Arbiter, and the Veto. These three things are not something any Agent can produce on its own — because their essence is “bearing consequences for decisions.” Agents, both legally and organizationally, cannot bear consequences.
Governance self-assessment:
Map your organization’s current status across the four red lines (visible / controllable / accountable / refusable). Which red line is weakest?
Does your team have a token budget for Agent skills? What’s the allocation basis?
Return to Part 1’s 30-second self-assessment — the tasks you marked as “loop-closable” now have an organizational-level interpretation. Layer 3a skill files are weapons; Layer 3b objective functions are direction. Weapons can be replicated; direction cannot.
Can you answer: which rules should not be written into a skill file — because those are lines that humans should hold.
References
Attebury, J. (2025). AX: A design discipline for the AI agent era. Dev.to. https://dev.to/attebury/ax-a-design-discipline-for-the-ai-agent-era-266e
Biilmann, M. (2025). The principles of Agent Experience (AX): Designing for the AI-driven consumer. Netlify Blog. https://www.netlify.com/blog/the-principles-of-agent-experience-ax-designing-for-the-ai-driven-consumer/
chigichan24. (2026). Mining hidden skills from Claude Code session logs with semantic knowledge graphs [crune]. Dev.to. https://dev.to/chigichan24/mining-hidden-skills-from-claude-code-session-logs-with-semantic-knowledge-graphs-2em8
Duan, P., Cheng, C.-Y., Li, T. J.-J., & Hartmann, B. (2024). UICrit: Enhancing automated design evaluation with a UI critique dataset. In Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology (UIST ‘24). ACM. https://arxiv.org/abs/2407.08850
Elish, M. C. (2019). Moral crumple zones: Cautionary tales in human-robot interaction. Engaging Science, Technology, and Society, 5, 40–60. https://doi.org/10.17351/ests2019.260
Mukherjee, A., & Chang, H. (2025). Agentic AI: Autonomy, accountability, and the algorithmic society. SSRN. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5123621
Nielsen Norman Group. (2025). The UX reckoning: Prepare for 2025 and beyond. NN/g. https://www.nngroup.com/articles/ux-reset-2025
Liu, Y., Wang, W., Feng, R., Zhang, Y., Xu, G., Deng, G., Li, Y., & Zhang, L. (2026). Agent skills in the wild: An empirical study of security vulnerabilities at scale. arXiv. https://arxiv.org/abs/2601.10338
Socially Interactive Agents Consortium. (2025). Socially interactive agents for preserving and transferring tacit knowledge in organizations. arXiv. https://arxiv.org/abs/2508.19942
Wen, J. (2026). Anthropic’s Head of Design on Cowork, AI-native design, and the future of UX [Video interview transcript]
Copyright © PrivacyUX Consulting Ltd. All rights reserved.

Joshua is a pioneer in Agentic UX (Agentic User Experience), with over 15 years of groundbreaking practice in the fields of artificial intelligence and user experience design. He was among the first to advocate for treating user privacy protection as a core principle of AI product design. In 2022, he founded Privacyux Consulting Ltd., where he serves as Chief Consultant, actively advancing privacy-centered innovation in medical AI products. Previously, he served as Chief Strategy Officer for Social AI (2022–2024), focusing on the design of privacy-conscious emotion recognition systems and mechanisms for user data autonomy.