Preface: In the previous installment, we saw the power structure of Design Critique loosening — when all five conceptual prototypes are Agent-generated, the focus shifts from “is this design good?” to “what is the rationale for choosing this direction?” But if you’re the one leading a team, the problem is more fundamental than critique: it’s not just designers using Agents — researchers are using them too. Anthropic’s Head of Design Jenny Wen says her team is “bottom-up, very democratic — insights and goals are shared with everyone, and everyone goes off to prototype.” Sounds beautiful. But your team isn’t Anthropic, and your designers aren’t Jenny Wen. When researchers, PMs, and engineers can all use Agents to produce prototypes, where is the designer’s “exclusive territory”? The moat question in this installment: How do you keep the team’s problem Frame from being hollowed out?
Author’s Note
In “When AI Becomes Standard Equipment for Design Teams,” a design director friend, after hearing personal AI use cases, furrowed his brow: “If five designers are all using Cowork simultaneously and each one’s Figma structure is different, what do we do?” At the time I gave him the RACI-AI model and the AIPET framework. A few months later, we talked again. He said the frameworks were useful, but the new problems were sharper — not inconsistency between designers’ structures, but a researcher bypassing the designer to produce a prototype directly, making the designer feel undermined. Redrawing role boundaries is ten times harder than unifying formats.
1. After “The Process Is Dead”: What Should You Build to Replace It?
Let’s first define this installment’s core concept. What is a problem Frame? It’s the judgment boundary that defines “which problems the Agent should not define on its own.” It’s not a score, not a policy — it’s the boundary-setting of the problem space. The Design Lead’s new job isn’t writing better proxy auditor skills (that was the previous installment’s work) — it’s setting the Frame. The process isn’t dead; it’s shifted from static to dynamic policy.
Tuesday morning. UX researcher Maya is preparing the next round of usability testing. Previously she had to wait for the designer to produce prototypes before she could start. Now she uses Cowork directly to generate three conceptual prototype variants, paired with her own research Skill library — interview script templates, analysis frameworks, inductive tagging systems — and in one afternoon forms “prototypes with embedded hypotheses.” Instead of waiting for the designer’s deliverables, the researcher has made her hypotheses tangible on her own.
The Design Lead sees this workflow and asks one question: “If the researcher can produce prototypes on her own, where does the designer fit in the workflow?”
Jenny’s approach is to let go. “Insights and goals are shared with everyone, and everyone goes off to prototype — ideas come from anywhere.” But in “After ‘The Design Process Is Dead,’” I did a structural deconstruction of this position: what Jenny calls “intuition” is built on over a decade of rigorous training accumulated at Dropbox and Figma. For senior designers, skipping steps and relying on intuition is “breaking the frame.” But for junior designers, processes like the Double Diamond are a necessary safety net. If your team copies Jenny’s “all intuition” approach and you have three juniors — you’ve just removed their guardrails.
So what should you do?
In “After ‘The Design Process Is Dead,’” the answer I proposed is “dynamic policy and evaluation”: the process is not “steps that must be completed,” but “judgment standards that dynamically adjust based on the quality of AI outputs.” Jenny’s third pair of new rules — from “measure twice, cut once” to “build real things, iterate, even discard multiple times” — is the operational face of this thinking. But the third rule only tells you “act fast”; it doesn’t tell you “what actions must not be fast.”
Risk level determines audit rigor. In the three-tier framework from “After ‘The Design Process Is Dead’”:
Jakob Nielsen and Sarah Davey’s AI Design Maturity 6-level model (2026) provides another ruler: Limited → Reactive → Developing → Embedded → Leading → Symbiotic. If your team is between Limited and Reactive — Maya’s Agent outputs need per-item designer review (still HITL). If already at Embedded — rules are set, the Agent runs on its own, humans only review exceptions (HOTL). In “When Claude Becomes Your Design Colleague,” I used L1/L2/L3 for a similar tiering: L1 = using the Agent as a tool, L2 = collaborating with the Agent, L3 = designing rules for the Agent to run.
The collision point is here: Nielsen’s 6 levels are more granular but tend toward the generic — he doesn’t address role-boundary-crossing scenarios like “a researcher using an Agent to produce prototypes.” The researcher crossing into prototyping is fundamentally a question of intent definition for role authorization: Maya’s Agent was authorized to “do research,” but it produced a “design prototype” — that exceeds the original intent spec. Nielsen’s model fundamentally assumes fixed role boundaries; from Limited to Symbiotic, none of it deals with “Role A’s Agent doing Role B’s work.” This is a structural blind spot across the entire AI maturity model family — one managers should note.
L1/L2/L3 maps more closely to Agent-era UX practice. Advice for managers: use Nielsen’s 6 levels for “where are we now” diagnosis, and L1/L2/L3 for “where are we going” roadmapping.
Back to Maya’s scenario. Her prototype lacks Design System Token alignment — button styles aren’t in the library, colors use hex values the Agent made up. The Design Lead’s new job isn’t “drawing it for her” — it’s “establishing quality admission standards for prototypes.”
This is the Frame.
Frame is not a score. NPS can tell you whether users are satisfied; a dark pattern scan can tell you whether there’s manipulative behavior; a VSD checklist can tell you whether values are aligned. But the decision “should Maya’s prototype enter usability testing?” — that’s not a score any single auditor can produce. It’s a framing judgment about “is this problem worth testing?” The Agent doesn’t do this.
And there’s an even more fundamental question: do the hypotheses that Maya’s Agent “synthesized” from research data actually exist in the source data?
2. Whose Agent Is Doing Whose Work: RACI-AI in Practice and the Hallucination Problem
RACI-AI (the AI-extended Responsibility Assignment Matrix) solves the formatting problem of “who does it, who’s accountable.” But if the insights synthesized by the Agent are themselves hallucinations, the Accountable party is shouldering a hollow responsibility. The manager’s second core output is the Arbiter — arbitrating the priority order when metrics conflict.
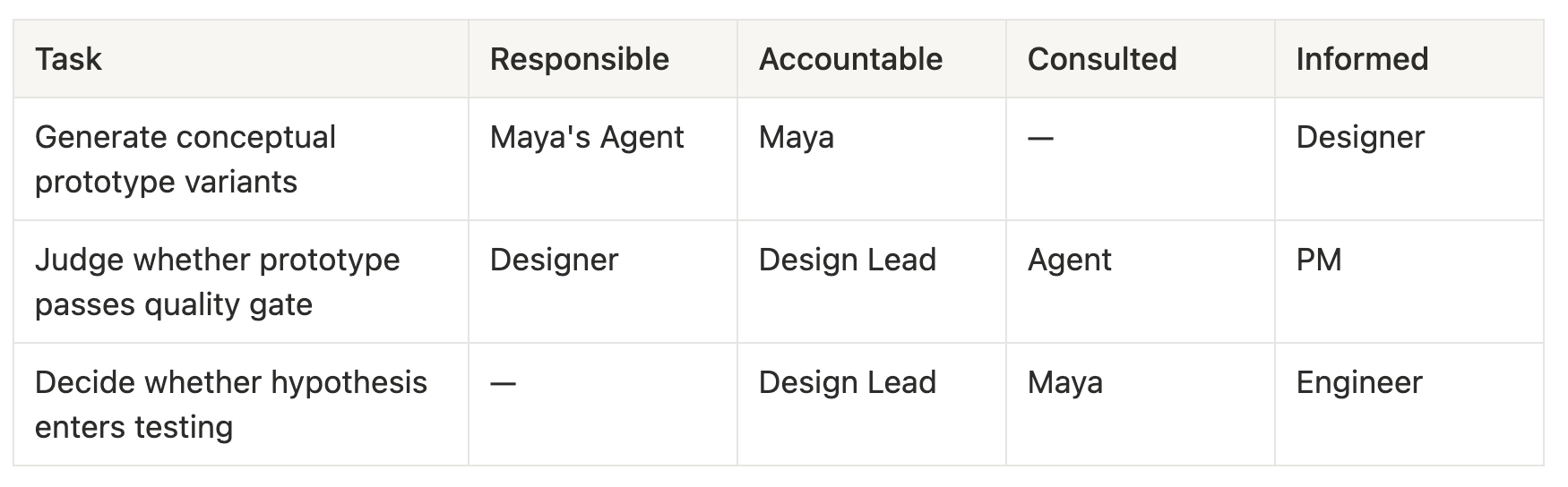
In “When AI Becomes Standard Equipment for Design Teams,” I provided a two-ruler architecture: the AIPET framework assesses task attributes (Agency / Interaction / Privacy / Experience / Trust), and the RACI-AI model assigns collaboration responsibilities (Responsible = AI does it / Accountable = human is responsible / Consulted = AI advises / Informed = AI notifies).
Running Maya’s scenario through it:
Looks clear. But the problem hides in the first row: Maya is Accountable — she’s responsible for her Agent’s output quality. But how does she verify the insights her Agent “synthesized”?
Nacke (2026) in his AI Responsibility Framework for UX Researchers identifies the core risk: AI hallucination in the synthesis phase. Insights the Agent synthesizes from research data — interview transcripts, usability test records, open-ended surveys — may not exist in the source data at all. It’s not “summarizing participant pain points” — it’s “fabricating a pain point that looks plausible but nobody actually said.”
If these “hallucinated insights” get written into Maya’s Skill library, get used to produce “prototypes with embedded hypotheses,” and then the designer refines them and the engineer implements them — the entire chain is built on a false foundation. What is the Accountable party in the RACI-AI shouldering? A research finding that never existed.
Jenny says she “wouldn’t hand everything over to Claude directly; we still rely heavily on our own judgment — deciding what to pursue and what to drop.” But in the responsibility-dilution undercurrent from “The AI Agent Governance Spectrum,” the problem is exposed: “When everyone is responsible, no one is truly responsible” — academia calls this a moral crumple zone, where responsibility is diluted across developers, deployers, and users (Mukherjee & Chang, 2025). Jenny’s team may be senior enough to “use judgment to filter out hallucinations,” but what about the three juniors on your team?
The authorization gap makes it worse.
The research insights in Maya’s Skill library come from users in the last round of interviews. Those users consented to participate in “usability testing,” but did not consent to having their pain points and behavioral patterns encoded into an Agent’s skill file, consumed by an Agent to produce prototypes. GDPR Article 9 is more direct: voice recordings constitute biometric data, triggering a higher protection tier. Research interview recordings uploaded to Dovetail then synthesized by AI — the original consent form almost certainly can’t cover this use. EU AI Act Article 53 delivers the final blow: once data enters model training weights, deletion is practically impossible. “Prevention is the only viable compliance strategy.”
One of the manager’s Frame responsibilities is defining “the boundary of what research data can be fed to Agents.” This isn’t the compliance department’s job — compliance sets the broad framework, but “which paragraphs of this interview transcript can go into the Skill library” is a judgment only the person designing the research process can make.
Then comes the Arbiter.
Scenario: Maya’s Agent produces a prototype. The Accessibility auditor says the button touch target is too small, violating WCAG 2.2. The Conversion auditor says enlarging the button drops the estimated CTR by 12%. The Ethics auditor says the copy phrase “limited-time offer” is an urgency pattern.
Three proxy auditors are fighting. Who wins?
This isn’t solvable by weighted averages. It’s a value ordering: “for this product, at this stage, facing these users, accessibility > conversion.” The Agent can lay all three conflicts in front of you. But the arbitration — “I choose accessibility, because 15% of our user base is over 65, and this is a medical product” — only a human can say that, because only a human can bear responsibility for the decision.
When three auditors conflict, the Arbiter’s tiebreaker rules follow this sequence: ① The context of the user population — who these people are and what their capability constraints are. ② Regulatory boundaries — medical, financial, children’s products have hard rules, no room for negotiation. ③ The long-term commitments of brand positioning — where your product needs to stand in three years. Only when all three of these bases fail to differentiate should you look at metric numbers. Numbers are the last resort, not the first instinct.
Anthony Franco in The AI Accountability Gap (UX Magazine, 2025) breaks accountability into three layers: Operational / Strategic / Executive. UX teams have long operated only at the operational layer (is the interface usable?); the strategic layer (should this feature ship?) and executive layer (who’s responsible when things go wrong?) were left to compliance and engineering. In “The Invisible Battleground of Agent Interface Design,” I extended this observation: this isn’t a capability problem — it’s a role definition problem. UX’s design object must expand from “the interface” to “the responsibility structure.”
The Arbiter is how UX reclaims the strategic layer. You don’t need to wait for compliance to tell you whether an urgency pattern is illegal. What you need is to establish a judgment rule within the team: “In medical scenarios, urgency patterns are always blocked, regardless of what conversion data says.” This rule doesn’t live in the skill file — it lives in your head. Write it down and it becomes Layer 3a (explicit rule); but “why this rule was chosen, and when this rule should be overturned” — that’s Layer 3b: objective function design.
Back to the final frame of Maya’s scenario. Her Agent produced a prototype with embedded hypotheses; the designer refined it; the engineer implemented it. After launch, a problem emerged: the “prototype carrying a false hypothesis” guided users toward a feature they didn’t understand. Who is Accountable in the RACI-AI?
Answer: the Design Lead. Because she had the authority (and responsibility) to say “this hypothesis doesn’t hold, send it back” before the prototype entered development.
But if the hypothesis itself was a hallucination synthesized by the Agent — how would the Lead know?
Prescription: Source Grounding Gate. Require that before any Agent-synthesized insight enters the Skill library, the researcher must be able to cite at least two original interview passages as sources (similar to RAG citation logic). This isn’t 100% hallucination-proof, but it filters out most “untraceable synthesized insights.” The Arbiter’s quality-side responsibility = ensuring this gate exists and is enforced. Without this layer of verification, the Accountable party in the RACI-AI is shouldering a hollow title.
3. Vision Shrinks from Five Years to Three Months: Design Leadership Through Assembling Fragments
When every team member’s Agent can produce prototypes with embedded hypotheses, the Design Lead’s Vision is no longer “what features will we build in the future” — it’s “which of these fragments point in the same direction, and which are fighting each other?” The new function of Vision = the highest-frequency application of Frame + Arbiter.
Jenny puts it directly: “I think vision covers at most three to six months. It can be a document, but it’s more helpful if it’s visual. So design still has enormous power here — bringing things together, weaving a coherent narrative through that stretch of time. It can even be a prototype.”
She then adds a key point that often gets overlooked: “We often have five teams doing very similar things and potentially duplicating effort. And what design can do is curate, bring cohesion, and point to a path where these become an ideal experience — instead of five disconnected loose parts.”
Boris Power in “The Bitter Lesson Has a Product Manager” offers a sharper framework: “Don’t build products for today’s models — build for the models six months from now.” If model capabilities jump a level every four to five weeks (Jenny herself admits Cowork undergoes a major UI overhaul almost every four to five weeks), then your vision is a hypothesis that keeps getting overturned.
Put these two statements together and the definition of vision changes.
Old vision was a destination: “In 18 months we’ll be here.” New vision is a direction: “Over the next three to six months, the Agent outputs from our five teams should converge in the same direction.”
This isn’t a downgrade — it’s an upgrade. Because “pointing out a direction” is harder than “defining an endpoint.” Defining an endpoint only requires a roadmap. Pointing out a direction requires you to simultaneously understand:
What each of the five teams is doing (what prototypes their Agents are producing)
Which prototypes have structural conflicts with each other (one team is simplifying a workflow while another team is adding regulatory checkpoints to the same workflow)
Which direction among these conflicts is closer to user needs three months from now
This is fundamentally the highest-frequency application of Frame (defining problem space boundaries) + Arbiter (arbitrating directional conflicts).
Back to the tool chain. In “When AI Can Reverse-Engineer an Entire App UI at the Atomic Level,” I mapped different AI/UX tools along a spectrum. From the manager’s perspective, the meaning of tools changes:
UXpilot + MagicPath: Upgraded from personal accelerator to “rapid hypothesis-materialization tool for the team.” Maya used it to produce three prototypes with hypotheses in one afternoon. But what the manager needs to ask isn’t “can it produce them?” — it’s “when five Mayas are producing simultaneously, how do I compare and converge?”
TheyDo: Upgraded from journey mapping platform to “Agent-consumable user journey structure.” TheyDo’s L0/L1/L2 hierarchy is itself a structured problem frame — the Agent reads it and knows “which node in this journey is a pain point, which node has the highest weight.” But the risk is on the flip side: if the journey map is just a ceremonial artifact pinned to the wall after the annual research debrief, the Agent reading it is just garbage in, garbage out.
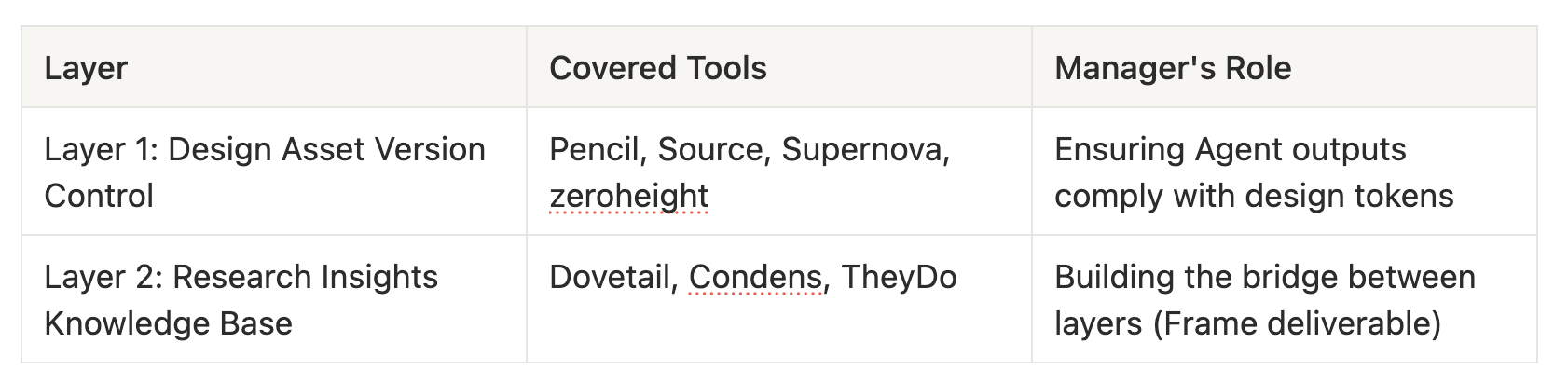
The living knowledge base in this installment resides in Layer 2 — the Research Insights Knowledge Base. Dovetail, Condens, and TheyDo cover interview records, journey maps, and insight tags. But they’re disconnected from Layer 1 (Pencil/Source/Supernova’s design asset version control) — you know user pain point X, but there’s no structural linkage to design decision Z about Figma component Y.
One of the manager’s Frame responsibilities is building the bridge between these two layers. Making “40% checkout page abandonment rate” automatically associated with “the checkout CTA button has been modified twice across the last three Agent outputs.” This isn’t a tool feature — no tool currently does this. It’s a problem structure defined by the manager — a Frame deliverable.
Jenny says vision can be a prototype. Maya says her Agent can produce three prototypes with hypotheses in one afternoon. Put these two statements together: the manager’s vision prototype = selecting the most directionally significant fragments from five teams’ Agent outputs and assembling them into an interactive prototype that says “this is what the experience should look like in three months.”
This is the new form of design leadership. Not drawing a vision deck nobody reads, but assembling a directional prototype that’s ready to be overturned at any time. Jenny’s rhythm — major overhaul every four to five weeks — is the shelf life of this prototype.
Does Your Researcher Have Their Own Skill Library?
Review the three sections you just read:
Frame: Defining “which problems the Agent should not define on its own” — whether Maya’s prototype should enter testing isn’t a question scores can answer.
Arbiter: Arbitrating the priority order of metric conflicts — when accessibility vs conversion vs ethics and three auditors are fighting, you are the referee.
Vision as direction: Assembling a direction from five teams’ Agent outputs — not a destination, but a direction.
The manager’s value doesn’t lie in writing better proxy auditor skills. That was the previous installment’s (Practitioner) job. The manager’s value lies in defining the problem Frame and arbitrating conflicts (Arbiter) — neither of which exists in a skill file, in a csv, or anywhere an Agent can produce on its own. Because their essence is “bearing consequences for judgments.”
Do a team self-assessment:
Does your researcher have their own Skill library? If so, do you know what’s in it? Do the research insights within it come from specific users, and do those users’ consent forms cover the use case of “being consumed by an Agent”?
Where does your team currently sit on Nielsen’s AI Design Maturity 6-level scale? Using L1/L2/L3, where should your team be heading?
Was there a “two auditors’ metrics fighting” situation last week? Who arbitrated? Was the rationale for the arbitration documented?
RACI-AI works within a team. But what about cross-departmentally?
The more fundamental question: the Arbiter can only arbitrate conflicts between existing metrics. But what if the metrics themselves are wrong? What if the definition of “quality score” excludes the needs of a certain user group? What if the authorization policy for research data doesn’t exist at all?
Those aren’t problems a manager can solve. Those are the governor’s problems.
Knowledge Base Architecture Preview: So far we’ve touched on the first two layers of the living knowledge base. The complete four-layer matrix (including Layer 3a explicit rules and Layer 3b objective function) will be expanded in the Governor installment. Here’s where you stand so far:
Next: Your team has started using Agents. But can the shelf life of your governance rules keep up with the speed at which Agents learn new skills? Even Anthropic’s own Cowork undergoes major overhauls every four to five weeks. And there’s an even sharper question: when Agent skill training itself costs tokens, “whose skill is worth investing in” becomes a performance issue — is a $2,400 token budget a cost or an investment? → Governor installment.
References
European Parliament & Council of the European Union. (2024). Regulation (EU) 2024/1689 of the European Parliament and of the Council laying down harmonised rules on artificial intelligence (Artificial Intelligence Act). Official Journal of the European Union, L Series. https://eur-lex.europa.eu/eli/reg/2024/1689/oj
European Parliament & Council of the European Union. (2016). Regulation (EU) 2016/679 on the protection of natural persons with regard to the processing of personal data (General Data Protection Regulation). Official Journal of the European Union, L 119, 1–88. https://eur-lex.europa.eu/eli/reg/2016/679/oj
Joshua is a pioneer in Agentic UX (Agentic User Experience), with over 15 years of groundbreaking practice in the fields of artificial intelligence and user experience design. He was among the first to advocate for treating user privacy protection as a core principle of AI product design. In 2022, he founded Privacyux Consulting Ltd., where he serves as Chief Consultant, actively advancing privacy-centered innovation in medical AI products. Previously, he served as Chief Strategy Officer for Social AI (2022–2024), focusing on the design of privacy-conscious emotion recognition systems and mechanisms for user data autonomy.