Preface: Anthropic’s Head of Design, Jenny Wen, says she “no longer spends long stretches focused on one project, but instead consults across five or six different projects simultaneously.” Sounds like a productivity boost. But place that statement inside a Design Critique and the picture shifts — when the PM points at five conceptual prototypes on the screen and asks “which one did you design?” and you can’t answer, because they were all Agent-generated. What you did was “select” and “refine.” The designer’s basis of legitimacy is migrating from “I drew it” to “I judged it.” The question in this article is: what is your basis for judgment? But the more honest question is: when all your judgments are executed by an Agent, what do you have left once the Agent is gone? The moat question in this installment: How do you keep your personal judgment from being replicated?
Author’s Note
Over the past few months I’ve been repeatedly hitting walls on the UICrit data pipeline — expert reviews can get into a csv, but turning them into a canvas that “the Agent can read, the Agent can act on, and the team can adjudicate” is more grueling than training a classification head. When I read Jenny describing how she uses Cowork to generate conceptual prototypes and then brings them back to Figma, my first thought wasn’t “impressive” — it was “where are her judgment criteria written down?” If the judgment lives in her head, that’s taste.
If it’s written in a UX_Skill.md, it’s a replicable rule. The gap between those two determines whether, in the Agent era, you are an “irreplaceable taste-holder” or a “fancier csv writer.”
Series Guide: This is the first of a three-part series. Each installment answers a different facet of the same question: what is your truly irreplaceable output?
1. Five Variants on the Table: The Power Structure of Design Critique Is Being Rewritten
When every conceptual prototype is Agent-generated, the focus of Design Critique shifts from “is this design good?” to “what is the rationale for choosing this direction?” The designer’s basis of legitimacy is no longer craft — it is the traceability of judgment.
Wednesday afternoon. Designer Kai lays five Agent-generated conceptual prototype variants on Figma and invites the PM, front-end engineer, and researcher to a Design Critique. The PM asks one question: “Which one did you design and which one did AI generate?” Kai can’t answer — because all of them were AI-generated. What he did was “select” and “refine.” The PM presses: “Then what was your basis for judgment?”
This scenario is not hypothetical. Jenny puts it bluntly: “These are often not prototypes anymore — they’re running features.” She uses Cowork to generate options, brings them back to Figma for polish, or builds them directly in Claude Code. The workflow has shifted from “designer draws → engineer implements” to “Agent produces a working prototype → designer judges on top of it.”
Jakob Nielsen calls this transition “the first UI paradigm shift in 60 years” — from command-based interaction to intent-based outcome specification (Nielsen, 2026). A usable intent requires three elements: desired outcome, behavioral constraints, and delegation boundary. When the PM asks “what is your basis for judgment?” in a critique, they are really asking “what does your intent spec say?”
Jenny’s workflow is already implicitly intent-driven: “sit next to the engineer and say here’s what I think.” But she does it on intuition, not in a structured way. Nielsen makes it explicit — the question is: can Jenny’s intuition be structured? If yes, that becomes a skill file — a distillable rule (discussed below). If not, that’s taste — something the Agent can’t learn.
Wong (2025) in NN/g’s research nails the flip side: vague prompts = outsourcing “undefined tasks” to the model. The output is stacked, repetitive, with bizarre hierarchy and falsely high information density. I felt this strongly while working with the Pencil pipeline in my dev environment — AI works more like making local variants “within an existing design system and file boundary,” not inventing a product from scratch. The ceiling of “one-sentence interface generation” = how far you’ve structured your design intent.
Back to the critique scenario. When the PM asks “which one did you make?” the underlying question isn’t about craft attribution — it’s about trust attribution: “Whose judgment should I trust?” When all five variants are AI-generated, the basis for trust can’t be “I drew this one.” It must be “my reason for choosing this one is —”
In “After ‘The Design Process Is Dead,’” one of Jenny’s five pairs of new rules directly addresses this pressure: from “Back everything with data” to “Flex intuition for quality.” This isn’t anti-data — it’s acknowledging that some judgments — especially “this direction feels wrong” — can’t be proven by metrics, yet are critical to outcomes.
iDesignGPT’s research provides the quantitative flip side: evaluating the design space of AI outputs using three metrics — coverage, diversity, and novelty (iDesignGPT, Nature Communications, 2026). This gives a critique a set of “discussable dimensions” — instead of the PM asking “which one is good?” they can ask “how much of the design space do these five variants cover? Are directions being missed?”
But the counterpoint is equally clear. In “After ‘The Design Process Is Dead,’” Stephanie Walter’s criticism hits the mark: survivorship bias — you only see the version where Jenny Wen got it right; you don’t see how many designers using the same approach produced garbage. In “When AI Can Reverse-Engineer an Entire App UI at the Atomic Level,” I discussed the JSON bloat problem: when AI mass-produces screens that “look like finished products,” can humans still review them?
This is the pressure point where you’re forced from Human-in-the-Loop (HITL — reviewing each one, pressing Y/N every time) to Human-on-the-Loop (HOTL — setting rules for the Agent, only reviewing results). Reviewing five variants one by one is manageable. Ten? Every day? Five designers using Agents simultaneously?
Prescription: Adjust audit rigor by risk level, using iDesignGPT’s three metrics as a tiered review framework. Within the dynamic policy framework from “After ‘The Design Process Is Dead’”:
Low risk (internal tools, exploration phase): Only check Coverage — do the Agent’s variants cover enough of the design space? Pass the threshold and they go into the repo for rapid iteration.
Medium risk (user-facing feature iterations): Both Coverage and Diversity must meet standards — the variants can’t just be micro-adjustments of the same direction. Before entering the repo, they must pass design token alignment + accessibility baseline.
High risk (involving user data, financial operations, health advice): All three metrics (including Novelty) are fully reviewed + a human Arbiter must be present. Each round of variants requires a human judgment: “is this a direction we dare to pursue?”
2. Skill Distillation: How to Feed Your Experience to the Agent
UX_Skill.md is the proxy auditor’s weapon — you write your judgment criteria as Agent-executable rules. But at its core it’s still Layer 3a: explicit knowledge, distillable, replicable. The VSD checklist and dark pattern scan you wrote are fancier csvs, not moats.
In “One AI Agent, 8 Million Views per Week,” Oliver Henry’s approach is straightforward: Larry has a skill file of over 500 lines, each one a rule learned from a mistake. Image dimensions wrong? Add a line. Text too small to read on mobile? Add a line. A particular hook only got 800 views while the previous one got 200K? Larry itself analyzes the difference and writes a new rule.
This is the minimal case of “making tacit knowledge explicit”: taking what you “can’t articulate but can do” in your head and writing it down, line by line, into an Agent-executable format. In “Verify, Don’t Just Look and Believe,” AgenSkill’s auditor-verifiable framework does the same thing — turning UICrit-level expert reviews (Duan et al., 2024) from static csvs into audit instructions the Agent can invoke.
But Jenny took a third path.
“After I mounted my personal notes folder to Cowork, the need for explicit skill and memory actually decreased.” Her approach isn’t writing experience as rules, but letting the Agent directly read her notes, her context, her thought process. Not a formalized skill file — a living knowledge base.
Oliver’s path (”One AI Agent, 8 Million Views per Week”) and Jenny’s path look opposite on the surface but structurally sit at two ends of the same problem:
Boris Power in “The Bitter Lesson Has a Product Manager” says outright: “Delete your CLAUDE.md“ — because Claude’s conversational memory is sufficient to understand your context; you don’t need to freeze experience in a static file. This tracks with Jenny’s approach.
But I’ll insert a warning here.
UICrit (Duan et al., 2024) froze experts’ UI critiques into csv — frozen means snapshot. The Agent can’t ask it questions, can’t have it learn new judgment criteria. The skill file is one step beyond csv — it’s updatable. But it’s still fundamentally Layer 3a: explicit rules, distillable. The proxy auditor checklist you wrote (VSD framework, persuasive design detection, dark/deceptive pattern detection) is a fancier csv, but still csv.
In “One AI Agent, 8 Million Views per Week” I wrote: skill files are fundamentally explicit knowledge, extremely easy for models to distill. Once uploaded to a public marketplace, platforms with stronger compute only need a few hundred such files to train a higher-level model with these “lessons-from-experience” built in. Ownership is yours, but the moat isn’t necessarily yours.
So where is the moat? Two directions: first, speed — the value of a skill file lies in its synchronous updates with the environment; a distilled model is a snapshot, and snapshots expire. Second, composability — a single skill file is easy to distill, but chaining multiple skill files into a specific business workflow — a “skill chain” — raises replication difficulty exponentially.
Even Jenny’s folder-as-memory, as long as it can be structurally read, can be distilled — the real moat isn’t in the format, but in update speed and composability.
Back to the critique scenario. The quality of Kai’s Agent output depends on what he feeds it. If his critique checklist is a skill file, a colleague can copy it and produce the same quality. If it’s intuitive notes in a folder, only his Agent can read it — but Jenny herself admits: “If you made me write a feature prioritization from scratch right now, it would take me longer than before.”
This is a deskilling signal. The Agent amplifies your output while eroding your independent capability without the Agent.
Prescription: Don’t pick one or the other. Mix by task type.
High-repetition, quantifiable judgments (contrast checks, accessibility baseline, design token alignment) → Write them in UX_Skill.md; let the Agent run them automatically. This is your proxy auditor arsenal.
Low-repetition, context-dependent judgments (is this feature worth building? does this direction feel wrong?) → Keep them in your folder / conversations; let the Agent learn from your thought process, not execute from your rules.
Critical reminder: The proxy auditor is the starting point, not the endpoint. Your UX_Skill.md upgrades you from HITL (reviewing one by one) to HOTL (setting rules for the Agent to run). But when the Accessibility auditor and the Conversion auditor fight, the skill file doesn’t say who wins. That judgment isn’t in the distillable Layer 3a — it’s in Layer 3b, which we’ll discuss in the next installment.
3. After the Tool Chain Is Reconfigured, Where Do You Stand?
Answer Capsule: Pencil (.pen) turns design files into JSON source code, so designers and engineers are finally conversing on the same artifact. But the tool only covers the “design asset version control” layer — it’s hardware, not soul.
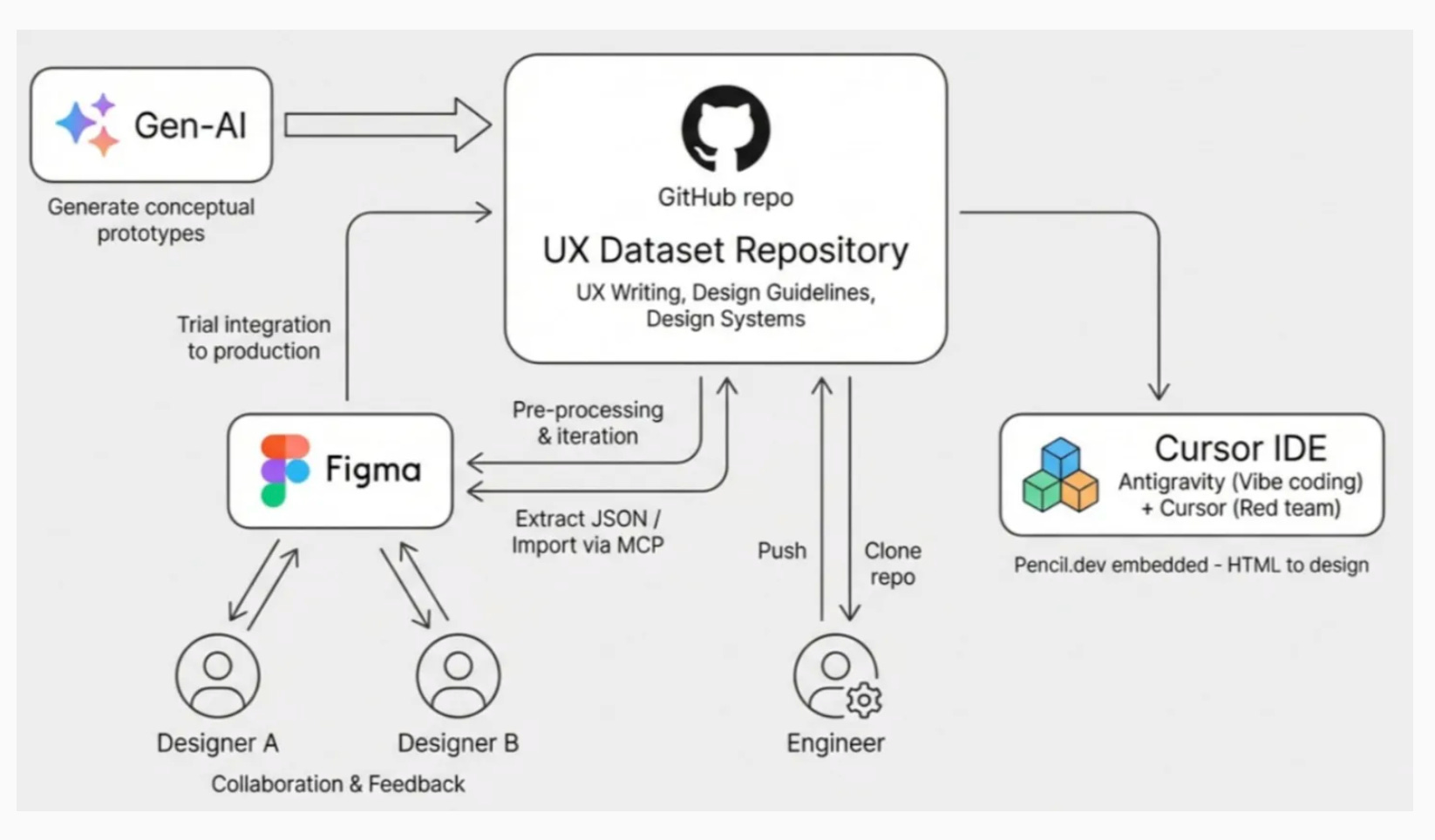
Jenny’s daily routine is “sit next to the engineer and say here’s what I think.” This sounds intuitive, but the underlying tool chain is no longer the traditional Figma → handoff → front-end implementation. In “When AI Can Reverse-Engineer an Entire App UI at the Atomic Level,” I mapped a new DesignOps pipeline: Gen-AI generates conceptual prototypes → Figma collaboration → Extract JSON / Import via MCP → UX Dataset Repository (GitHub) → Cursor IDE (Pencil.dev). The core shift: design assets flow bidirectionally between Figma, GitHub, and Cursor as code / structured data.
The question isn’t what each tool can do individually — it’s which judgment layers they collectively cover, and what they can’t.
Tool Judgment Layer Covered What It Can’t Cover Cursor + MCP Agent CRUD operations on the design canvas Directional judgment: “should this feature exist?” Pencil (.pen) Design asset version control (JSON in Git) Review governance when JSON bloats Paper.design Rapid prototype iteration (Canvas layer) Long-term design asset pipeline (cloud files aren’t Git-friendly) UXpilot Heuristic checks + lightweight proxy Arbitration across conflicting metrics (accessibility vs conversion)
These four tools together cover the first layer of a “living knowledge base” — design asset version control. Pencil + Source + Supernova + zeroheight manage the .pen JSON, design tokens, and component libraries. This pipeline is hardware.
But hardware isn’t soul. Nowhere in this pipeline is any node asking: “Should this feature exist?” “Is this direction harmful to users?” “Of these five variants, which direction aligns with our three-month vision?” Those judgments live in Layer 2 (research insights) and Layer 3b (objective function design) — and those layers currently have no tool coverage.
Back to the final frame of the critique scenario. The front-end engineer in the critique isn’t looking at Figma mockups — they’re looking at .pen JSON diffs. Designers and engineers are finally conversing on the same artifact — that’s good. But the PM is excluded. They can’t read JSON diffs. All they can ask is “why did you choose this one?”
And your answer — “because my judgment was —” — is your entire basis of legitimacy in the Agent era.
You’ve Made Ten Variants. But Who Decides Which One Ships?
List every design task you did last week. Which ones are “loop-closable” — with clear inputs, measurable outputs, and outputs that can modify rules to form a self-correcting loop? Which ones require your tacit judgment — context, taste, “this feels wrong”?
Write the former into a skill file and hand them to the Agent. Leave the latter in your folder, making it a knowledge base that your Agent can read but others can’t replicate.
Then think: next time at the Design Critique, when the PM asks “which one did you make?” — how are you going to answer?
But say you’ve written an excellent proxy auditor skill — the VSD checklist passed, the dark pattern scan shows zero red flags, accessibility baseline is OK. Then the Accessibility auditor and the Conversion auditor start fighting. Your UX_skill.md doesn’t say who wins.
That judgment isn’t in Layer 3a. It’s in Layer 3b.
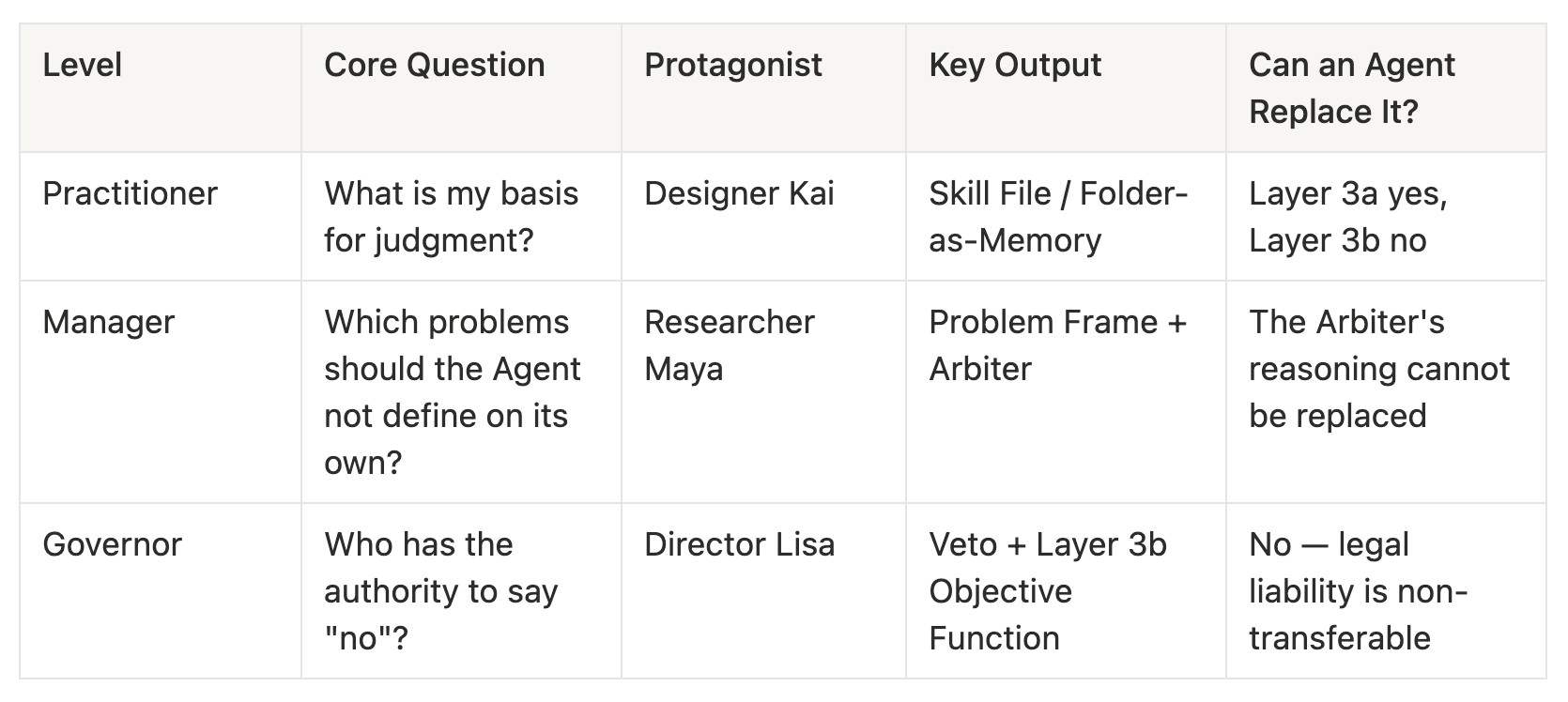
The explicit rules discussed in this installment — skill files, VSD checklists, dark pattern scans — all belong to what I provisionally call Layer 3a: writable, distillable, replicable. Layer 3b (objective function design) is the subject of the next two installments: the Manager installment discusses problem Frames and Arbiters; the Governor installment discusses Veto power and non-distillable judgments.
Next: You’ve made ten variants of your conceptual prototype. But who on the team decides which ones enter the repo? If five designers are all using Agents simultaneously and each has different critique standards, what then? And there’s an even more fundamental question: the researcher has an Agent too — she can produce prototypes on her own, so where does the designer fit in the workflow? → Manager installment.
References
Duan, P., Cheng, C.-Y., Li, T. J.-J., & Hartmann, B. (2024). UICrit: Enhancing automated design evaluation with a UI critique dataset. In Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology (UIST ‘24). ACM. https://arxiv.org/abs/2407.08850
Nielsen, J. (2026, March 26). Intent by discovery: Designing the AI user experience. Jakob Nielsen on UX.
Wen, J. (2026). Anthropic’s Head of Design on Cowork, AI-native design, and the future of UX [Video interview transcript]. article_293.md.
Zhu, Q., Luo, J., & Nagai, Y. (2026). iDesignGPT enhances conceptual design via large language model agentic workflows. Nature Communications, 17, Article 68672. https://doi.org/10.1038/s41467-026-68672-1
Joshua is a pioneer in Agentic UX (Agentic User Experience), with over 15 years of groundbreaking practice in the fields of artificial intelligence and user experience design. He was among the first to advocate for treating user privacy protection as a core principle of AI product design. In 2022, he founded Privacyux Consulting Ltd., where he serves as Chief Consultant, actively advancing privacy-centered innovation in medical AI products. Previously, he served as Chief Strategy Officer for Social AI (2022–2024), focusing on the design of privacy-conscious emotion recognition systems and mechanisms for user data autonomy.